Your cart is currently empty!


1. Introduction: Why GPU Scheduling Is the Core Challenge in Digital Human Systems
Over the past few months, the NavTalk team has been focused on building a real-time, voice-driven digital human system. The core objective is straightforward: enable users to have natural conversations with digital avatars in any scenario — and deliver an experience that feels nearly indistinguishable from interacting with a real person. Achieving this goal, however, requires massive backend compute power — especially from GPUs.
In the early phases of development, we addressed two “visible” experience challenges:
▪️ Audio-video synchronization: By optimizing our audio and video streaming algorithms, we achieved millisecond-level alignment between the avatar’s lip movements and the audio output.
▪️ Response latency: Through accelerated model inference and fine-tuned parameter tuning, we reduced response time to near-instant levels — comparable to natural human reaction.
Once these foundational issues were resolved, a new and more complex challenge emerged: how to reliably manage GPU resources under high concurrency.
NavTalk’s user traffic doesn’t follow a steady linear curve — it spikes unpredictably during events like livestreams, large online classes, or enterprise-scale training sessions. In such high-demand scenarios, a poorly designed GPU scheduling system could easily lead to:
▪️ Sudden GPU exhaustion: New users are blocked from entering the service.
▪️ Unstable GPU allocation: Users get assigned to unavailable or unstable GPUs, resulting in poor user experience.
▪️ Uncontrolled costs: Simply scaling up GPU capacity might solve performance issues — but it leads to explosive cost increases.
In short, while audio-video sync and latency tuning address the single-user experience, GPU scheduling determines whether the system can survive at scale with thousands of concurrent users. That’s the core challenge we’re tackling in this blog — how to build a GPU architecture that’s both dynamically scalable and operationally stable under high load.
2. Full User Connection Flow
To help readers better understand the design of our GPU scheduling system, let’s start with the most fundamental part — the full lifecycle of a user connection. This corresponds to the left half of the architecture diagram: what exactly happens inside the system when a user opens the digital human interface on the frontend?
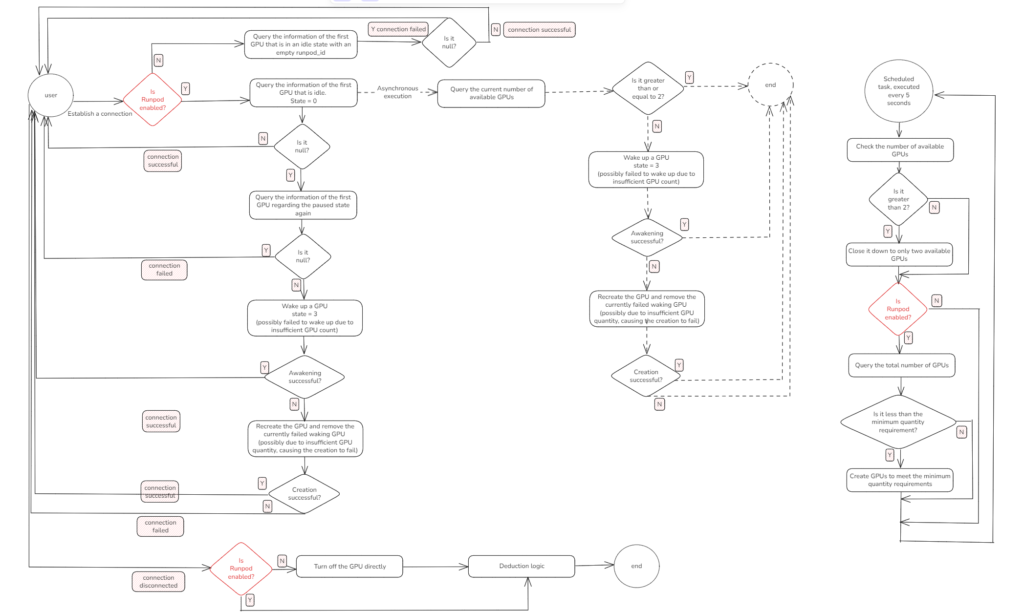
2.1 From Page Click to GPU Assignment
When a user enters the system by clicking the page, the backend first attempts to assign a GPU for the connection. At this point, the system performs a key check: Is the Runpod cloud extension enabled?
💡 What is Runpod?
Runpod is a cloud platform designed for high-performance computing (HPC) tasks. It offers elastic GPU resources suitable for use cases like AI inference, training, and video rendering. Unlike traditional cloud providers, Runpod supports fast GPU instance launch or destruction via API. In our system, Runpod functions as a cloud GPU expansion pool. When local resources run out, the system dynamically creates GPU instances via Runpod to supplement compute power and ensure stability under high concurrency.
▪️ If Runpod is not enabled:
The system will only search the local database for idle GPUs (state = 0).
▪️ If found → Assign it to the user and proceed with connection.
▪️ If not found → Connection fails; user cannot access the service.
▪️ If Runpod is enabled:
The system will first prioritize using local GPUs (where runpod_id = null and state is idle). If no local GPU is available, it will attempt to connect to Runpod and create a new cloud GPU instance.
This design gives the system elastic scalability, allowing it to continue serving users even under high concurrency by dynamically expanding resources.
2.2 GPU State Definitions
Throughout the GPU lifecycle, we use the state field to indicate its current status:
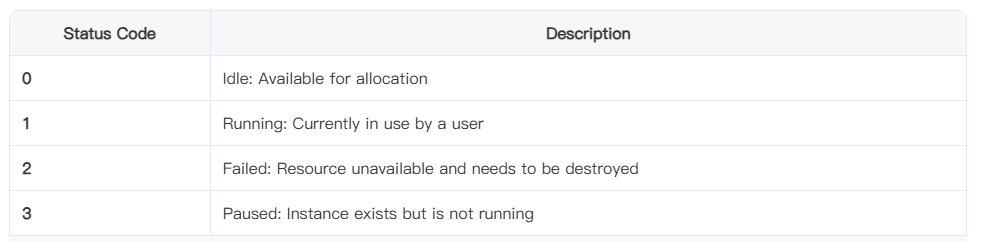
This state machine is the foundation of our GPU scheduling logic. Every incoming user connection request drives a state transition and decision based on this model.
2.3 Connection Setup and Failure Handling
Once a GPU is successfully assigned, the system attempts to establish a WebSocket (or similar) connection with the user:
▪️ If connection succeeds
The GPU state is updated to running, and the user immediately enters the service.
▪️ If connection fails
The system enters a fault-tolerant recovery process and executes the following steps in order:
1)Check for paused GPUs (state = 3)
If found, the system attempts to wake it up.
▪️ If wake succeeds → retry connection
▪️ If wake fails → destroy the GPU and proceed to the next step
2)Recreate GPU instance
Destroy the failed GPU → trigger creation logic (local or Runpod)
▪️ If creation succeeds → retry connection.
▪️ If it fails → system has exhausted all available GPU resources.
3)Resource exhaustion fallback
If both local and cloud resources are depleted, the system returns a connection failure response and prompts the user to wait for the next available GPU.
2.4 Flow Summary
This entire process ensures that even under GPU scarcity or peak concurrent usage, users won’t face a frozen screen or total service failure:
▪️ Prefer idle GPUs
▪️ If none available, attempt to wake paused GPUs
▪️ If wake fails, destroy and recreate
▪️ Only return failure if no resources can be recovered
This fault-tolerant and elastic strategy significantly increases service availability in high-concurrency scenarios.
3. Asynchronous Threading for High Concurrency: Preparing the Next GPU in Advance
In real-world usage, we observed a critical issue: when a user connects and no GPU is immediately available, the system must wait for one to be awakened or created — a process that can take several seconds or more. This delay severely affects user experience.
To mitigate this, we designed an asynchronous background thread that is triggered every time a user successfully connects to a GPU. This thread quietly prepares the next available GPU in advance, without blocking the current connection. This mechanism greatly improves the chances of “instant connections” for the next user — and corresponds to the middle section of our architecture diagram.
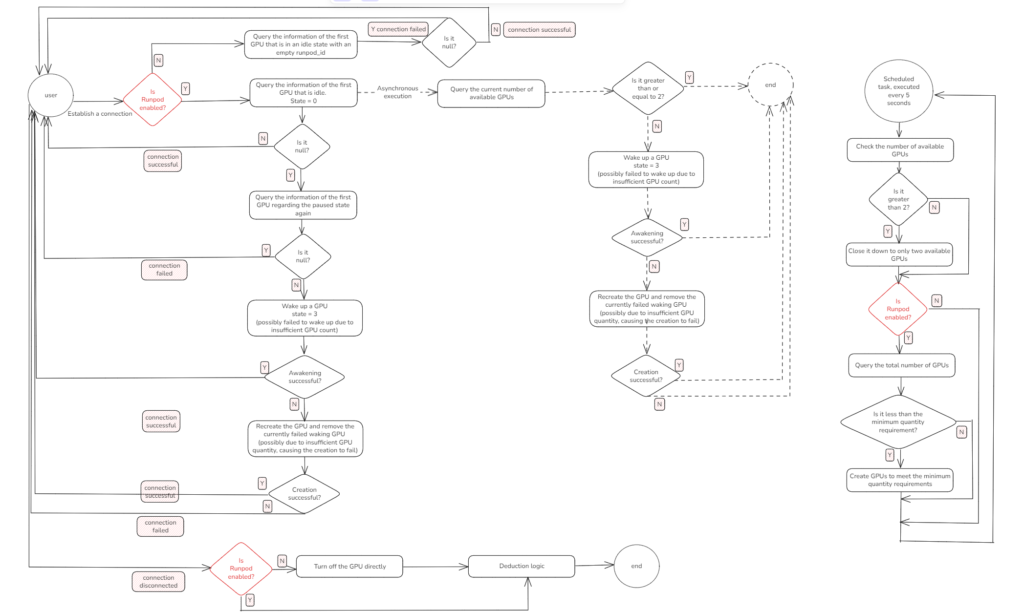
What Does the Asynchronous Thread Actually Do?
▪️ It starts immediately after the current user successfully connects to a GPU.
▪️ In the background, it attempts to wake up a paused GPU (state = 3).
▪️ If no paused GPU is available, it triggers the creation of a new GPU instance via Runpod.
▪️ The whole process runs asynchronously and does not block the frontend connection logic, enabling the system to serve the current user while preparing resources for the next.
Here’s a quick example:
User A connects successfully → The backend asynchronously spawns a thread → That thread wakes or creates the next GPU → When User B arrives, there’s already a GPU ready for instant use.
Why This Matters?
Waking or creating a GPU is a slow operation — it can take several seconds or even longer. On the other hand, a user’s connection request is a fast operation. If we wait until the user clicks “connect” before provisioning a GPU, we’re already too late.
Our new strategy flips this around:
Don’t wait for the user to arrive — have the GPU ready beforehand.
With this design, most users connect instantly because a GPU is already available, dramatically improving success rate and user-perceived responsiveness.
4. Runpod Elastic Scaling: Automatically Adding and Releasing GPUs Without Wasting Resources
To strike the balance between performance and cost, the NavTalk GPU scheduling system integrates an elastic resource scaling mechanism powered by Runpod. The goals are clear:
▪️ Avoid wasting GPU resources (optimize cloud cost)
▪️ Maintain high availability during traffic spikes (avoid connection failures)
The core of this design comes down to two configurable parameters + one background scheduler, as shown on the right side of the architecture diagram.
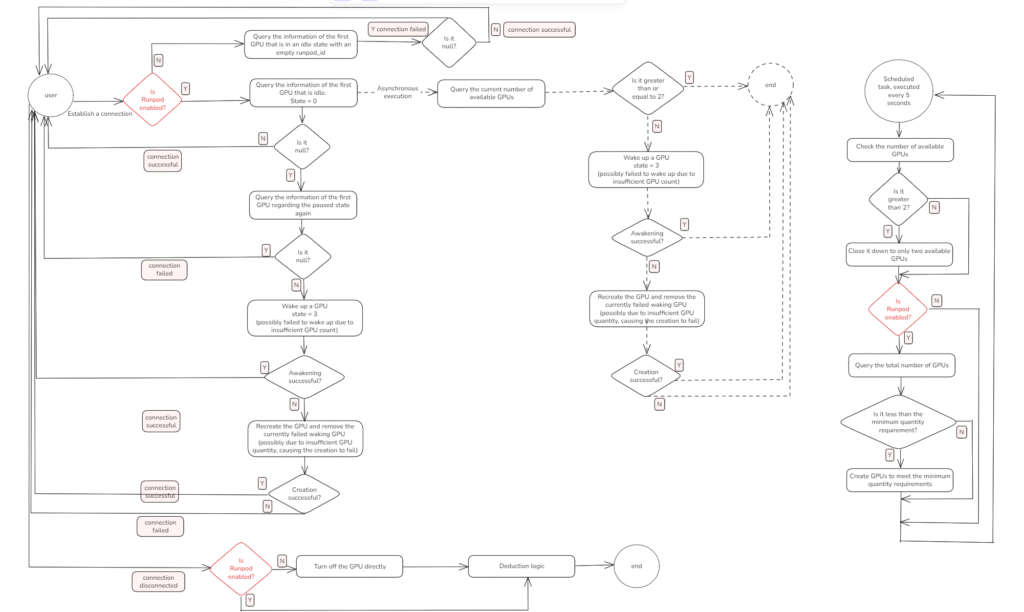
4.1 Two Key Parameters: MIN_RUNNING_GPU and FREE_RUNNING_GPU
The GPU auto-scaling strategy in our system is governed by two configurable parameters:
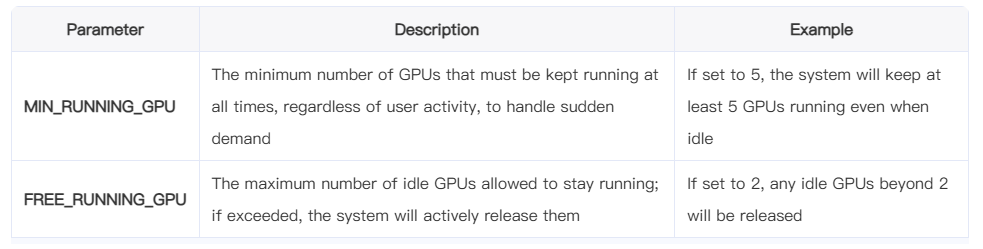
Together, these two parameters define the minimum guarantee and maximum buffer of GPU resources, striking a balance between availability and cost.
4.2 Periodic Scheduler: Auto-Scaling Logic Every X Seconds
We’ve implemented a lightweight scheduler that runs every X seconds and adjusts GPU resources dynamically:
1)Check idle GPU count (state = 0)
2)If idle GPUs > FREE_RUNNING_GPU:
▪️ Reclaim idle resources
This approach avoids excess cloud GPU charges, especially after traffic spikes when unused Runpod instances might linger.
3)If idle GPUs < MIN_RUNNING_GPU:
▪️ Automatically trigger GPU creation (via Runpod or locally)
4)Ensure total GPU count meets baseline requirements
Since launching a new GPU takes time, this scheduling loop helps the system stay ahead of user demand, especially during unexpected traffic bursts. By prewarming GPUs through proper
MIN_RUNNING_GPUconfiguration (e.g., 3–5), we absorb user surges gracefully.
This periodic check runs continuously, keeping the system in a “just right” state — not overprovisioned, not underpowered.
5. Enterprise Clients and Dedicated GPU Deployment
NavTalk serves a diverse user base: from short-burst consumer sessions to long-running enterprise applications. To accommodate both usage patterns, we’ve adopted a dual-pool architecture:
▪️ General users share the common GPU resource pool.
▪️ Enterprise clients can self-provision GPUs by renting their own instances and hosting services in their own environments.
These client-owned GPUs are completely excluded from our shared scheduling logic.
5.1 Why Separate Deployment for Enterprise?
GPUs are valuable and often scarce during peak demand. We’ve encountered several clients with special requirements, such as:
▪️ Nonstop live streams lasting several hours
▪️ Always-on corporate digital assistants
▪️ High-frequency, multi-user concurrent access systems
If these clients used the public GPU pool, it could lead to:
▪️ Long-term GPU occupation → lower availability for general users
▪️ Costly reconnections due to premature resource release
▪️ Increased complexity in scheduling logic
To address this, we recommend and support a clean separation:
▪️ We help enterprise clients deploy their own GPUs (via Runpod, AWS, or on-premises)
▪️ Their digital human services run with dedicated deployment + private endpoints
▪️ Our system automatically detects and excludes these GPUs from all scheduling, allocation, and release logic
▪️ This setup ensures maximum stability for enterprise use without compromising the fairness or efficiency of the shared GPU pool.
6. Architecture Deep Dive: From GPU Request to Final Release
In the NavTalk real-time voice system, we’ve built a complete GPU scheduling and lifecycle management mechanism to ensure service stability even under heavy concurrent traffic. The full design is reflected in the system architecture diagram.
In this section, we’ll walk through the architecture from left to right — tracing how a typical connection request is handled, including GPU assignment, state transitions, async creation, connection setup, and resource recycling.
6.1 User Request Entry: Connection & Thread Dispatch
When a user clicks “Start Digital Human” on the frontend, the browser sends a WebSocket or HTTP request to the backend.
1)The backend immediately creates a thread (managed by a thread pool) to handle GPU allocation for this user.
2)The system checks whether Runpod cloud GPU support is enabled:
If disabled: only locally deployed GPUs are considered.
If enabled: both local and cloud GPUs participate in unified scheduling.
6.2 GPU Allocation Priority: Idle → Wake → Create
The system attempts to assign GPUs in the following priority order:
1)Find idle GPU (state = 0)
If available, assign it immediately and establish connection.
2)Wake paused GPU (state = 3)
If no idle GPU exists, attempt to wake up a paused one.
▪️ If successful → proceed with connection.
▪️ If failed → destroy and move to next step.
3)Async GPU creation
If no usable GPU is found, directly trigger GPU creation (no need to wait for exhaustion).
▪️ If Runpod is enabled → call API to spin up a cloud GPU instance.
▪️ Otherwise → start a local GPU.
This means every user connection proactively triggers GPU wake-up or creation to ensure resources are ready for the next user.
6.3 Connection & State Transition
Once a thread successfully obtains a GPU, it attempts to establish a live connection:
If successful: the GPU state updates to running, and the user begins interacting with the digital human.
If it fails (e.g., port unreachable, WebSocket timeout),the system either:
▪️ Releases and rebuilds the GPU, or
▪️ Marks it as failed for later cleanup by the scheduler.
Real-time state tracking is critical for scheduling stability — every connection dynamically updates GPU status for the system’s global view.
6.4 Resource Reclaiming & Periodic Scheduler
A lightweight internal scheduler runs every few seconds (typically every 5s) to monitor and adjust GPU usage.
Reclaim excess idle GPUs:
▪️ If the number of idle GPUs > FREE_RUNNING_GPU:
▪️ Prefer to release cloud GPUs (Runpod) to avoid unnecessary billing.
▪️ Retain local GPUs for cost efficiency.
Replenish GPU capacity:
▪️ If total GPUs < MIN_RUNNING_GPU:
▪️ Trigger async creation of new GPUs to maintain readiness.
▪️ Prevent connection failures during traffic spikes.
This automated cycle ensures that the system continuously adapts to traffic in a “just-right” state — no overuse, no under-preparation.
7. Looking Ahead: From Rule-Based to Intelligent Scheduling
The current NavTalk GPU scheduling system already provides strong support for high concurrency, elastic resource management, and overall service stability. However, we’re also aware that much of the logic still depends on manually configured rules — such as toggling Runpod support or setting static GPU thresholds.
To better handle future workloads that are more dynamic and complex, we’re planning a series of key upgrades aimed at smarter, automated control.
7.1 Intelligent Activation of Runpod Cloud Resources
At present, whether to enable Runpod is still manually configured. In the future, we aim to automatically activate cloud GPU support based on real-time signals such as user activity trends and GPU utilization metrics. This would reduce unnecessary overhead while ensuring rapid scaling when demand spikes.
7.2 Smarter GPU Auto-Scaling Strategies
The current values for MIN_RUNNING_GPU and FREE_RUNNING_GPU are statically defined, and the scheduling logic is rule-based. Looking forward, we plan to implement more intelligent GPU scaling strategies that adapt GPU capacity in real time — striking a better balance between utilization efficiency and cost control.
7.3 A User-Aware Queueing Mechanism
Under extreme concurrency, when all GPUs are in use, the current system simply returns a connection failure. To improve this, we will introduce a frontend-visible queueing mechanism. Users will see their position in the queue and an estimated wait time, while the system will intelligently trigger GPU provisioning based on queue status — improving transparency and fairness in the user experience.
Conclusion: Evolving from Initial Architecture to Continuous Optimization
Building a GPU scheduling system capable of supporting high-concurrency real-time services is never a one-off project. As our business scales, user scenarios diversify, and concurrency patterns evolve, we will continue to refine our scheduling system—moving from rule-based logic toward intelligent automation, and from “just enough” to truly optimal.
We hope this architecture not only powers NavTalk today, but also provides valuable insight and reference for other teams facing similar challenges.
We’re always open to discussion—let’s work together to bring digital humans into an era of truly real-time · intelligent · stable performance.








Leave a Reply