Your cart is currently empty!


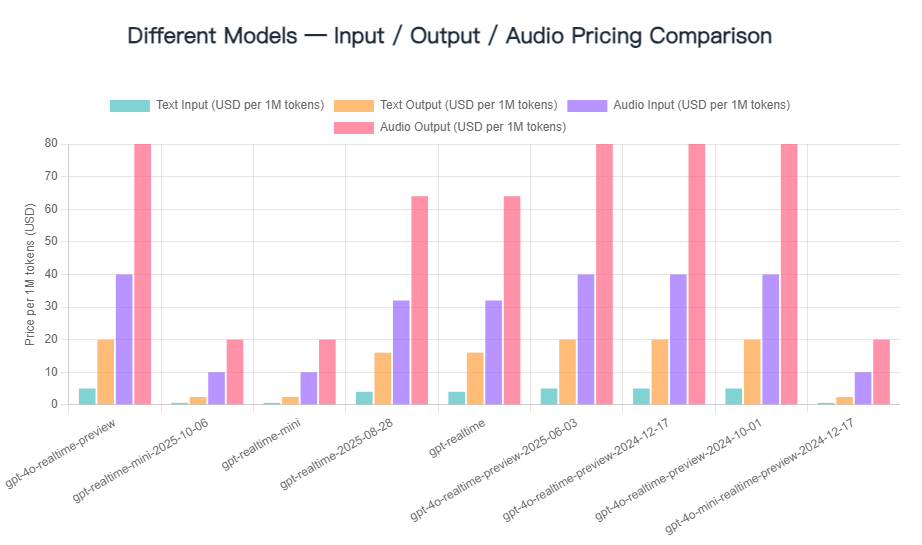
1.Overview of All Models and Official Pricing
2.New Model Cost Comparison: No Prompt / 100 Prompts / 1000 Prompts
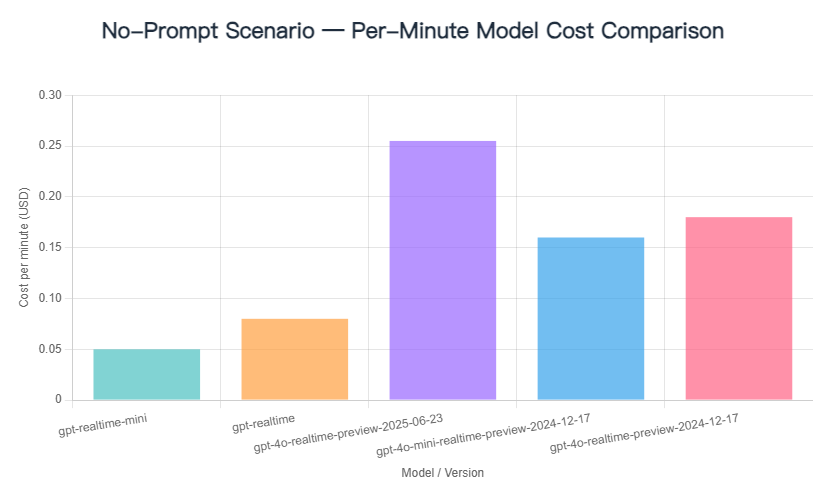
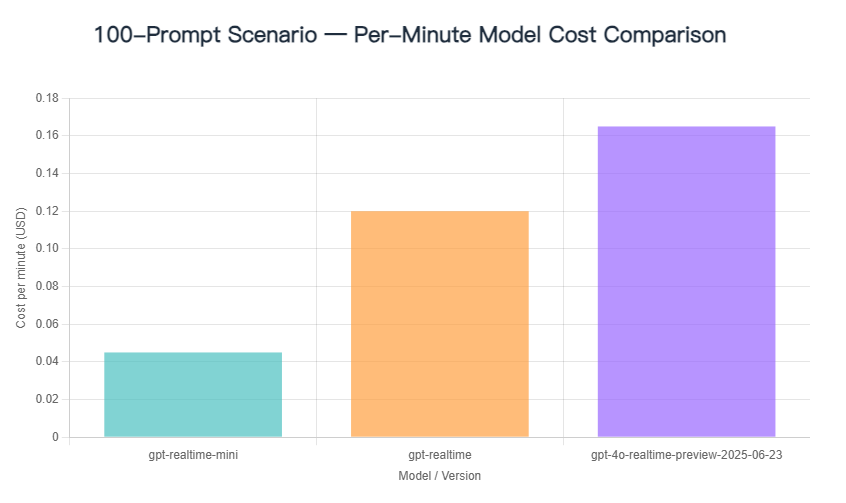
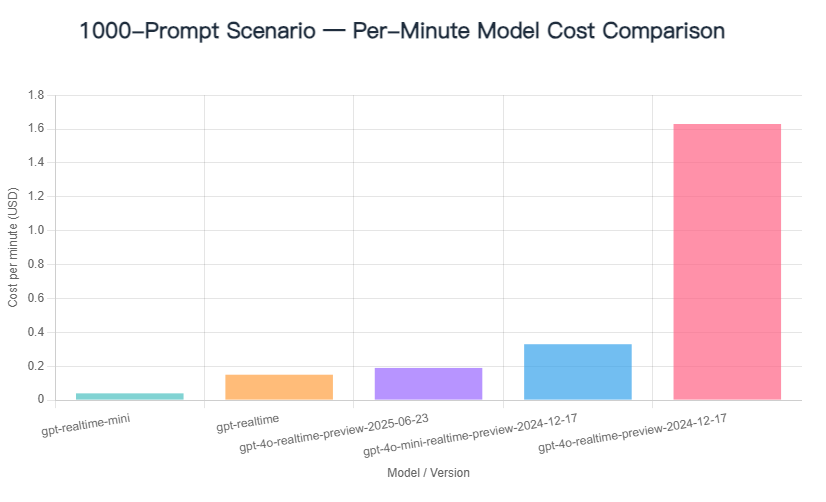
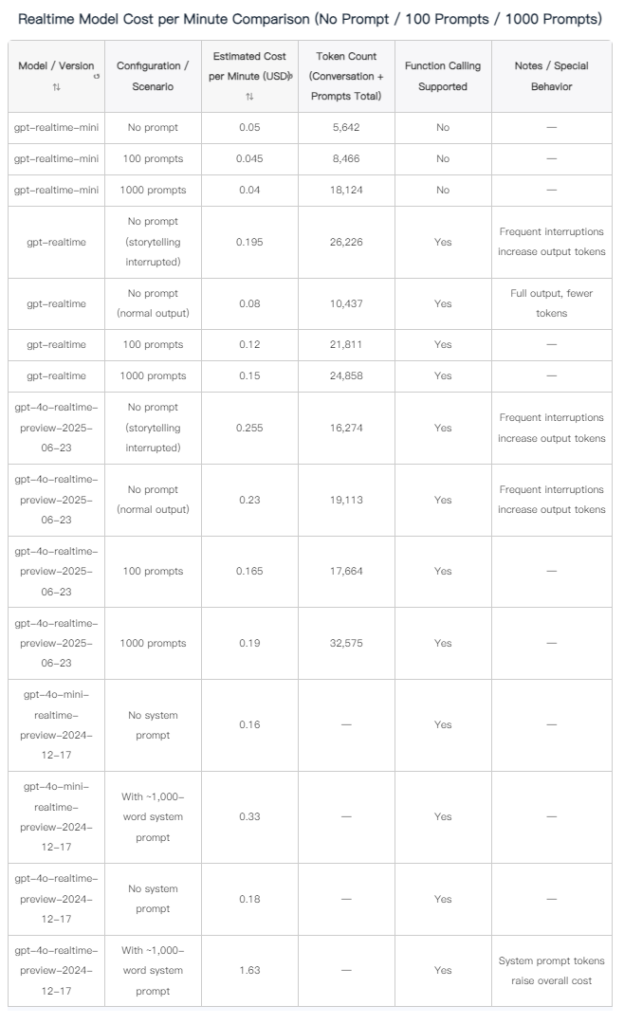
A single test has inherent variability. The main factors influencing the cost per minute of conversation are as follows:
- Token Count: The more input and output tokens there are, the higher the cost. Each model is billed per million tokens, and more tokens mean greater computational requirements.
- Number of Prompts: More prompts (such as 100 or 1000 prompts) increase the number of input tokens, thereby raising the cost per minute.
- Conversation Type: Frequent interruptions in the conversation (such as interrupting a story) result in more output tokens, which increases the cost.
- Audio vs. Text: Processing audio input and output is more costly than text processing, which increases the cost per minute.
- Model Complexity: More complex models (like gpt-4o-realtime-preview) are more expensive than simpler models (like gpt-realtime-mini).
3. Testing Process
3.1 gpt-realtime-mini Charging Test
3.1.1 Initial State
Initial total consumption: $1.87, Initial total tokens: 5,190,576
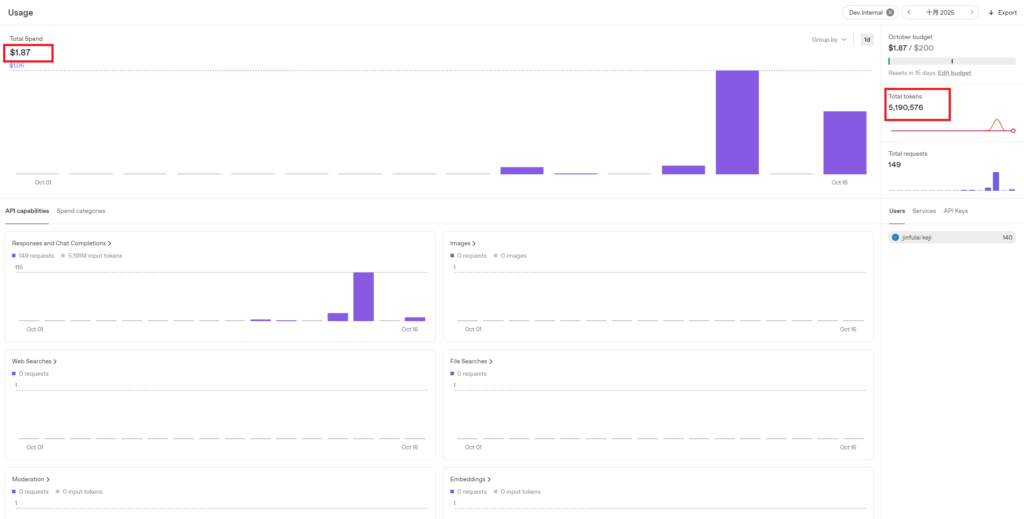
3.1.2 First Test: No Prompt, 2-Minute Length Conversation
Consumption amount: $0.1, Tokens consumed: 5,642. Estimated consumption per minute: $0.1/2 = $0.05.
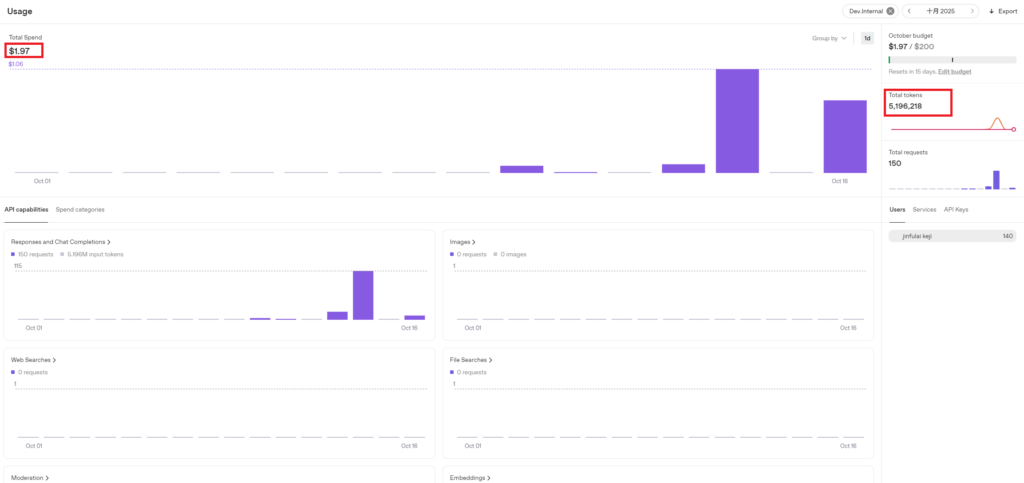
3.1.3 Second Test: 100 Prompts, 2-Minute Length Conversation
Consumption amount: $0.09, Tokens consumed: 8,466. Estimated consumption per minute: $0.09/2 = $0.045.
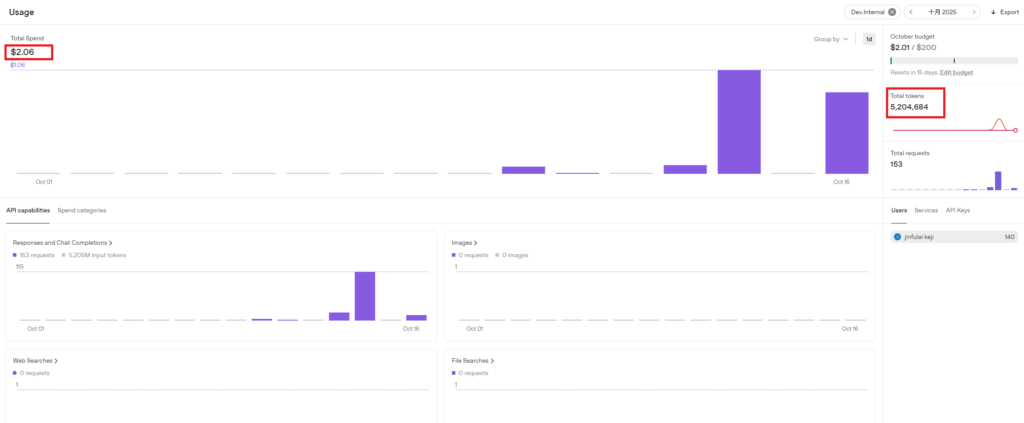
3.1.4 Third Test: 1000 Prompts, 2-Minute Length Conversation
Consumption amount: $0.08, Tokens consumed: 18,124. Estimated consumption per minute: $0.08/2 = $0.04.
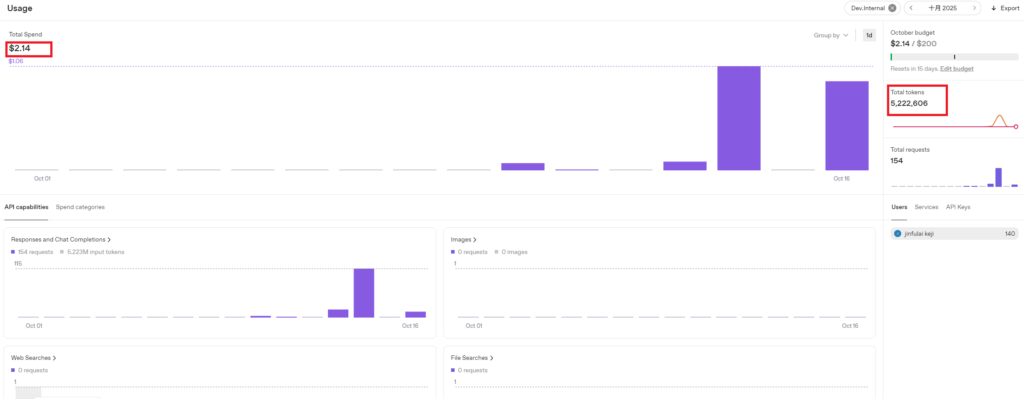
3.2 gpt-realtime Charging Test
3.2.1 Initial State
Initial total consumption: $2.53, Initial total tokens: 5,677,480
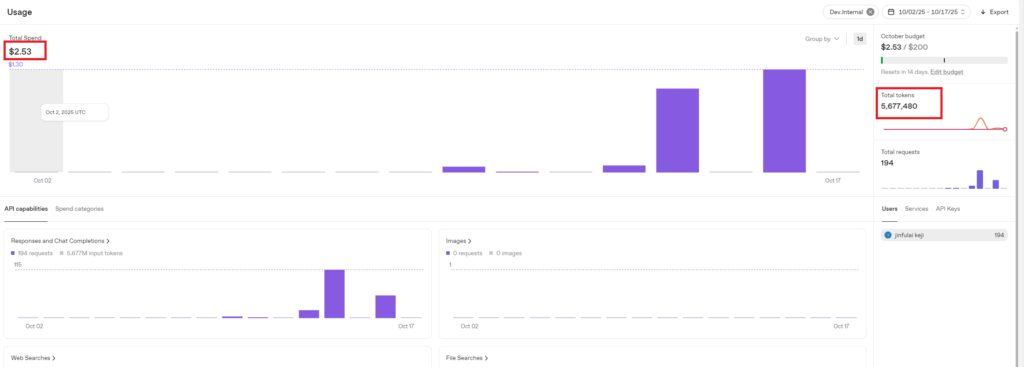
3.2.2 First Test: No Prompt, 2-Minute Length Conversation
Consumption amount: $0.39, Tokens consumed: 26,226. Estimated consumption per minute: $0.39/2 = $0.195.
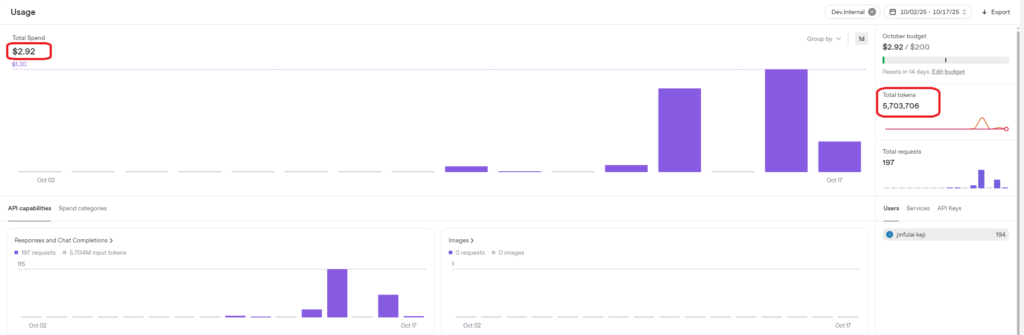
3.2.3 Second Test: No Prompt, 2-Minute Length Conversation — Surprised by the Higher Cost Compared to gpt-realtime-mini, So Retested
Consumption amount: $0.16, Tokens consumed: 10,437. Estimated consumption per minute: $0.16/2 = $0.08.
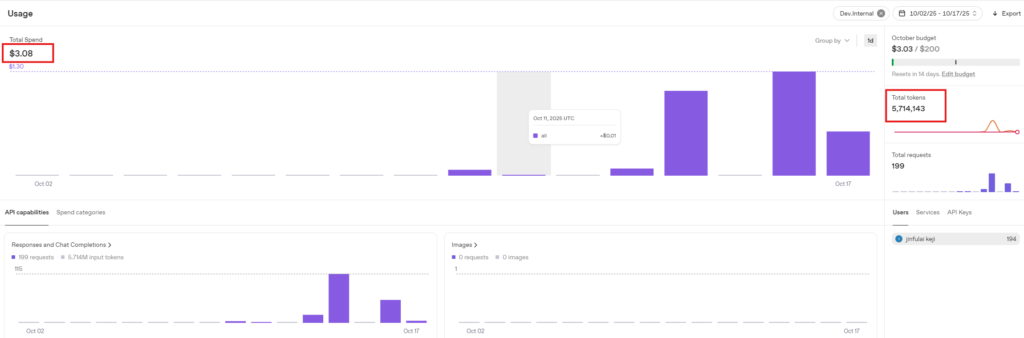
First Test:
The conversation required the model to tell a story, but I interrupted it each time, asking it to change the story halfway through. This likely resulted in more output tokens.
Second Test:
The conversation was about asking the model to tell me today’s news, and I waited for it to finish speaking each time. This resulted in fewer output tokens. When recalculated:
26226 / 10437 * 0.08 = $0.201, and the adjusted price is close to the first test’s output.
3.2.4 Third Test: 100 Prompts, 2-Minute Length Conversation
Consumption amount: $0.24, Tokens consumed: 21,811. Estimated consumption per minute: $0.24 / 2 = $0.12.
Prompt:
A polite restaurant waiter takes orders from customers in a cozy modern bistro. The waiter greets guests warmly, offers seating by the window, and recommends today’s specials: grilled salmon with lemon butter, black pepper beef rice, creamy pasta, and tiramisu dessert. Drinks include iced lemon tea, latte, and red wine. The waiter speaks clearly, confirms each order, adjusts spice levels if needed, and offers suggestions for pairing dishes. The restaurant ambiance is calm with soft jazz music. The waiter remains friendly, attentive, and professional, ensuring a pleasant dining experience from ordering to final payment.
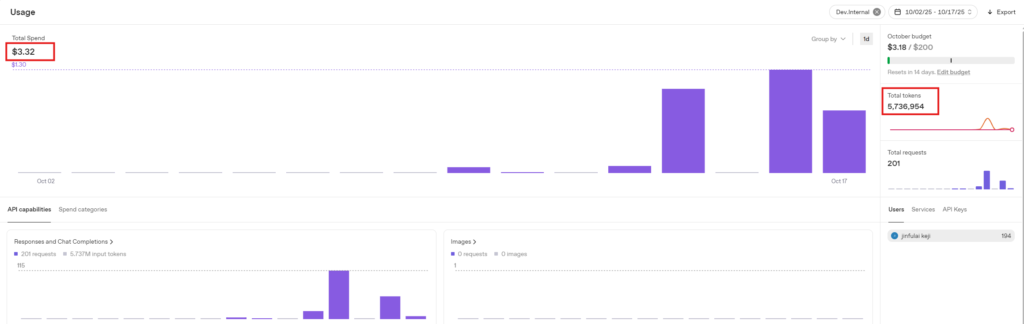
3.2.5 Fourth Test: 1000 Prompts, 2-Minute Length Conversation
Consumption amount: $0.3, Tokens consumed: 24,858. Estimated consumption per minute: $0.3 / 2 = $0.15.
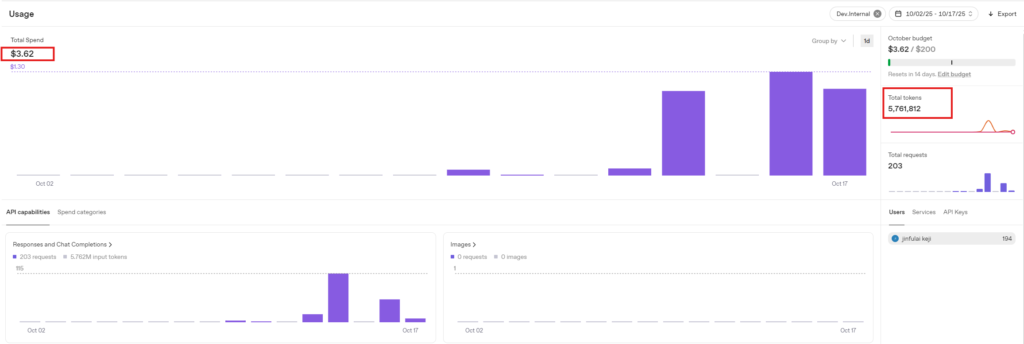
Compared to the third test, the token count is similar, and the number of system prompt tokens does not affect the cost per minute of the conversation.
3.3 gpt-4o-realtime-preview-2025-06-23 Charging Test
3.3.1 Initial State
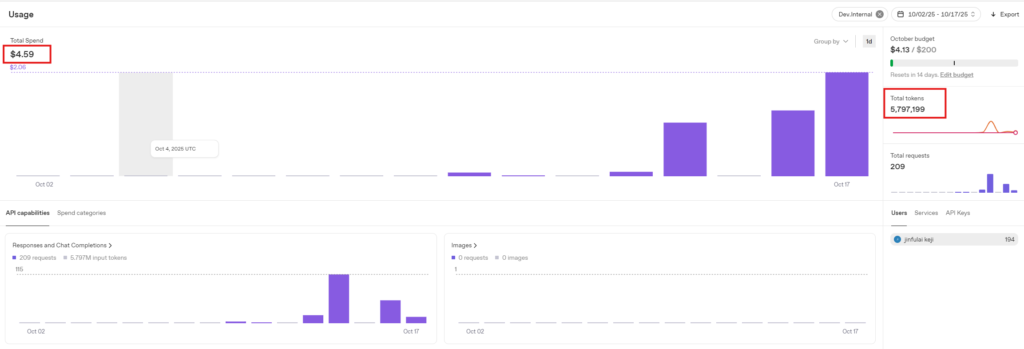
Initial total consumption: $3.62, Initial total tokens: 5,761,812
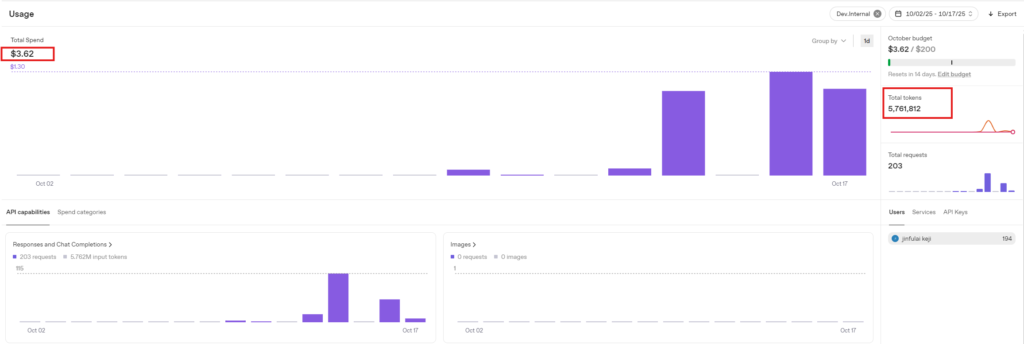
3.3.2 First Test: No Prompt, 2-Minute Length Conversation
Consumption amount: $0.51, Tokens consumed: 16,274. Estimated consumption per minute: $0.51 / 2 = $0.255.
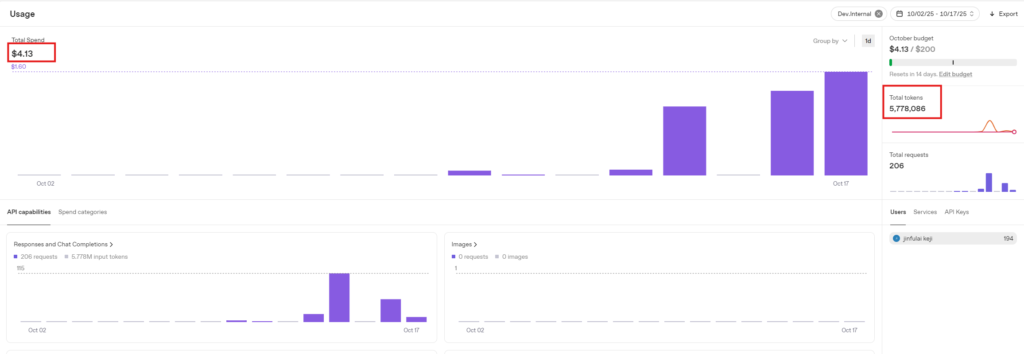
3.3.3 Second Test: No Prompt, 2-Minute Length Conversation — Surprised by the Price Again, Retested
Consumption amount: $0.46, Tokens consumed: 19,113. Estimated consumption per minute: $0.46 / 2 = $0.23.
First Test:
The conversation involved asking the model to tell a story, but I interrupted it each time, asking it to switch to a new story halfway through. This likely resulted in more output tokens.
Second Test:
The conversation was still about asking it to tell a story, and I continued to interrupt it each time during the conversation.
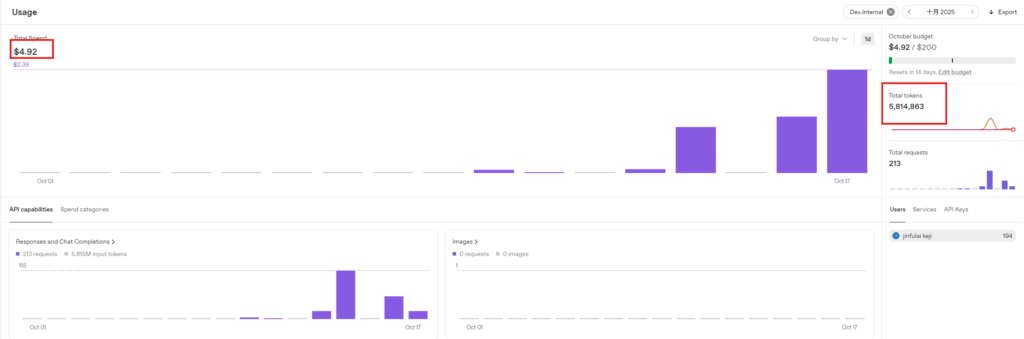
3.3.4 Third Test: 100 Prompts, 2-Minute Length Conversation
Consumption amount: $0.33, Tokens consumed: 17,664. Estimated consumption per minute: $0.33 / 2 = $0.165.
Prompt:
A polite restaurant waiter takes orders from customers in a cozy modern bistro. The waiter greets guests warmly, offers seating by the window, and recommends today’s specials: grilled salmon with lemon butter, black pepper beef rice, creamy pasta, and tiramisu dessert. Drinks include iced lemon tea, latte, and red wine. The waiter speaks clearly, confirms each order, adjusts spice levels if needed, and offers suggestions for pairing dishes. The restaurant ambiance is calm with soft jazz music. The waiter remains friendly, attentive, and professional, ensuring a pleasant dining experience from ordering to final payment.
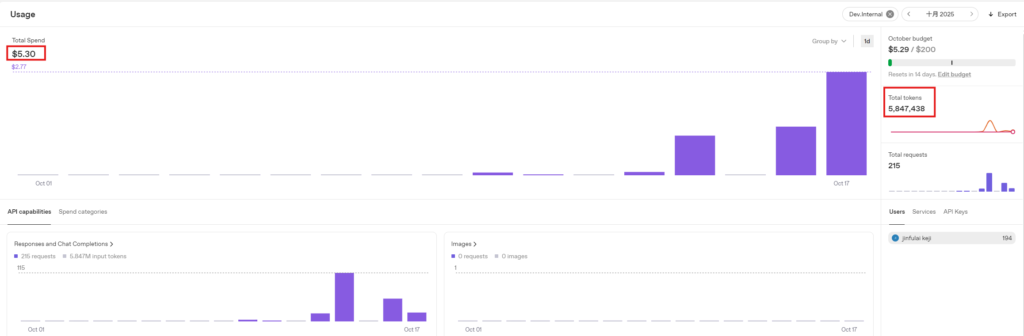
3.3.5 Fourth Test: 1000 Prompts, 2-Minute Length Conversation
Consumption amount: $0.38, Tokens consumed: 32,575. Estimated consumption per minute: $0.38 / 2 = $0.19.








Leave a Reply